

Tags
- migrations
- update
- 쟝고
- stack
- distinct
- Article & User
- Vue
- regexp
- 스택
- drf
- create
- 백트래킹
- delete
- 완전검색
- 트리
- SQL
- 그리디
- 큐
- 이진트리
- Queue
- Django
- outer join
- N:1
- 통계학
- count
- Tree
- ORM
- M:N
- 뷰
- DB
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Notice
Recent Posts
Link
데이터 분석 기술 블로그
퀵 정렬 (Quick Sort) 본문
퀵 정렬
"피벗(Pivot)을 기준으로 작은 값과 큰 값을 나누면서 정렬하는 빠른 정렬 알고리즘"
- 분할 정복(Divide & Conquer) 방식 사용
- 평균 시간복잡도 O(n log n) → 빠른 정렬 방법 중 하나
- 실제로 가장 많이 사용되는 정렬 알고리즘 중 하나
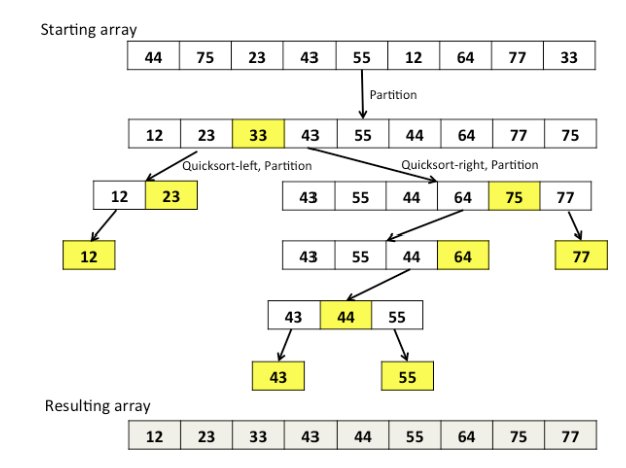
퀵 정렬 동작 원리
- 피벗(Pivot) 선택
- 리스트에서 특정한 요소를 피벗으로 선택 (보통 첫 번째, 마지막, 중간 값 중 하나)
- 분할(Partitioning)
- 피벗을 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽으로 이동
- 재귀 호출(Recursion)
- 왼쪽과 오른쪽 리스트를 다시 퀵 정렬 수행
- 크기가 1 이하가 되면 정렬 종료
# Pseudo Code
FUNCTION QuickSort(arr)
IF length(arr) <= 1 THEN
RETURN arr # 리스트 크기가 1 이하이면 정렬 완료
SET pivot TO arr[length(arr) / 2] # 중앙값을 피벗으로 선택
SET left TO empty list
SET middle TO empty list
SET right TO empty list
FOR EACH element x IN arr DO
IF x < pivot THEN
ADD x TO left
ELSE IF x > pivot THEN
ADD x TO right
ELSE
ADD x TO middle
END FOR
RETURN QuickSort(left) + middle + QuickSort(right) # 재귀 호출하여 정렬된 리스트 반환
END FUNCTION
# Full Code
def partition(arr, low, high):
pivot = arr[high] # 마지막 요소를 피벗으로 선택
i = low - 1 # 작은 값들의 위치를 추적하는 인덱스
for j in range(low, high):
if arr[j] < pivot: # 피벗보다 작은 경우 왼쪽으로 이동
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1] # 피벗을 올바른 위치로 이동
return i + 1 # 피벗 위치 반환
def quick_sort_inplace(arr, low, high):
if low < high:
pivot_index = partition(arr, low, high)
quick_sort_inplace(arr, low, pivot_index - 1) # 왼쪽 부분 정렬
quick_sort_inplace(arr, pivot_index + 1, high) # 오른쪽 부분 정렬
# 테스트
arr = [5, 3, 8, 4, 2, 7, 6, 1]
quick_sort_inplace(arr, 0, len(arr) - 1)
print("퀵 정렬 결과 (인플레이스):", arr)퀵 정렬의 시간복잡도
| 경우 | 시간복잡도 |
| 최선 (O(n log n)) | 균등하게 분할된 경우 |
| 평균 (O(n log n)) | 일반적인 랜덤 데이터 |
| 최악 (O(n²)) | 이미 정렬된 상태에서 최악의 피벗 선택 |
✅ O(n log n)으로 빠른 정렬 가능
❌ 최악의 경우 O(n²) → 항상 좋은 피벗을 선택하는 것이 중요!
피벗 선택 방법
| 피벗 선택 방식 | 설명 | 장점 | 단점 |
| 첫 번째 요소 | 리스트의 첫 번째 값을 피벗으로 선택 | 구현이 쉬움 | 정렬된 데이터에서는 최악의 O(n²) |
| 마지막 요소 | 리스트의 마지막 값을 피벗으로 선택 | 구현이 쉬움 | 정렬된 데이터에서는 최악의 O(n²) |
| 랜덤 피벗 | 리스트에서 무작위로 피벗 선택 | 최악의 경우 방지 가능 | 랜덤 함수 호출 추가 비용 발생 |
| 중앙값(Median of Three) | 첫 번째, 중간, 마지막 값 중 중앙값 선택 | 일반적으로 좋은 성능 보장 | 비교 연산 추가 필요 |
보통은 "랜덤 피벗" 또는 "중앙값(Median of Three)": (len(arr) // 2)을 사용
- 랜덤 피벗 → 최악의 경우를 방지하기 쉬움
- 중앙값 피벗 → 정렬된 데이터에서도 좋은 성능 유지
퀵 정렬의 장단점
장점
- 평균적으로 O(n log n)으로 빠름
- 추가 메모리 필요 없음 (제자리 정렬, O(1))
- 실제로 가장 많이 사용되는 정렬 알고리즘 중 하나
단점
- 최악의 경우 O(n²) 발생 가능 (피벗을 비효율적으로 선택하면 성능 저하)
- 재귀 호출이 많아 스택 오버플로(Stack Overflow) 발생 가능
2025.01.20 - [데이터 사이언스/알고리즘] - Stack Overflow
결론
퀵 정렬은 일반적으로 가장 빠른 정렬 중 하나지만, 피벗 선택이 중요합니다. 실제로 정렬 라이브러리(Pyhton의 sorted())에서도 퀵 정렬 변형이 사용됩니다.
'데이터 사이언스 > 알고리즘' 카테고리의 다른 글
| Heap Overflow (0) | 2025.02.15 |
|---|---|
| Stack Overflow (0) | 2025.02.14 |
| 삽입 정렬 (Insertion Sort) (0) | 2025.02.12 |
| 선택 정렬 (Selection Sort) (0) | 2025.02.11 |
| 버블 정렬 (Bubble Sort) (0) | 2025.02.10 |
'데이터 사이언스/알고리즘' Related Articles
more

